Counter AI
Study various aspects of adversarial/counter AI. Based on my directed study at UWAPL Fall 2023.
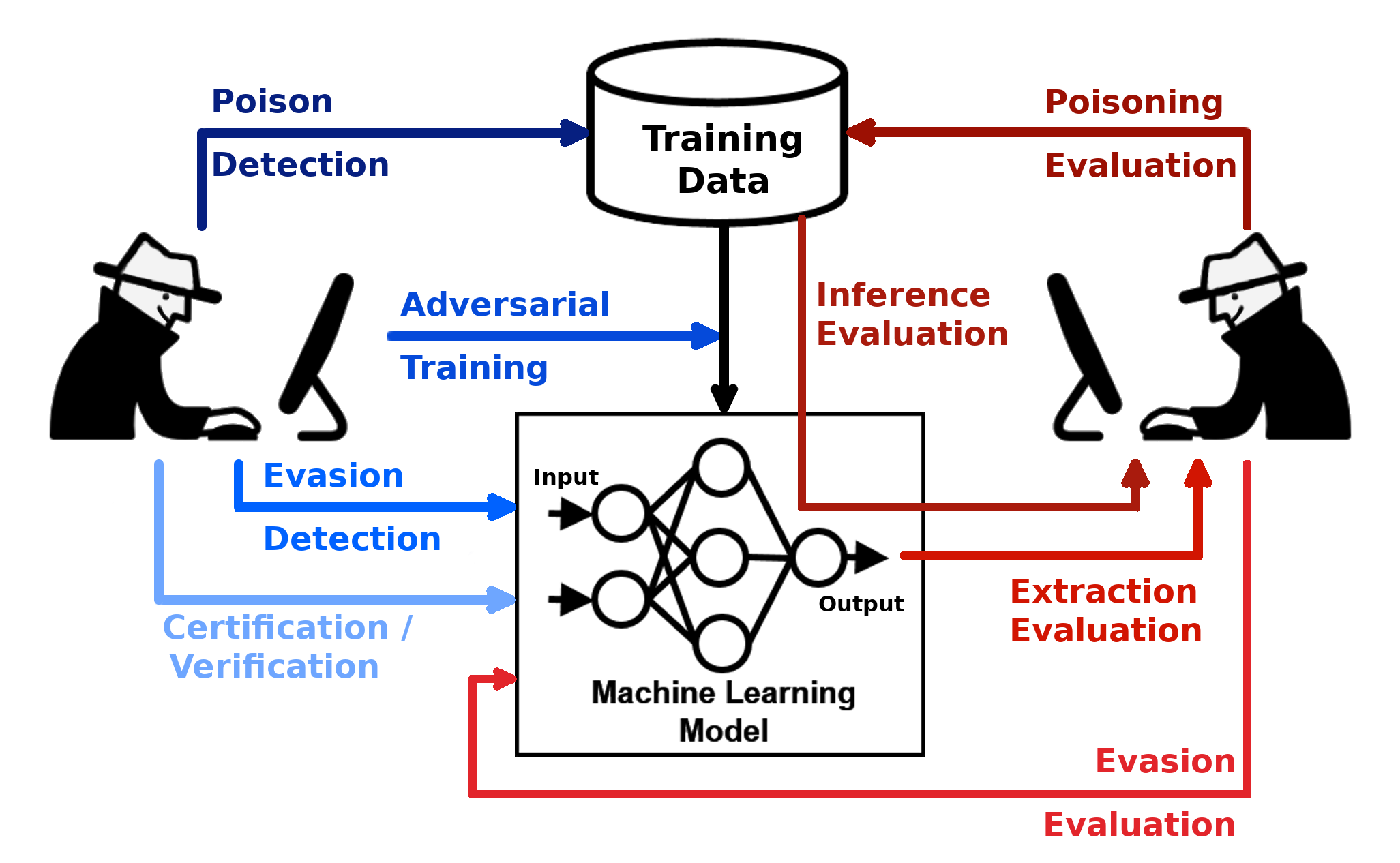
In this project, I explore various areas of adversarial AI including attack/defense strategies, standardized evaluation metrics, and real world applications. The above image is from the adversarial robustness toolbox, and it captures the various techniques for exploiting and protecting AI models. Of course, our end goal is to achieve robustness against all types of adversaries by studying both attack and defence strategies! Below is the introduction from my synthesis paper.
Introduction
Artificial Intelligence has become increasingly prevalent in our daily lives in various applications ranging from spam mail detection to self-driving cars. As AI becomes more accessible to various users, trust becomes a key factor in whether an AI-powered system is frequently used or not. User trust in AI models is influenced by various factors such as the privacy of personal data, its performance given specific tasks, consistency in varying situations, and even the explainability of AI alogrithms. Trust is especially crucial in safety-criticalsituations such as assisted driving, where misjudgment involving pedestrians could cause significant damage.In these cases, users will use AI technologies only if they can fully trust them. As such, advancements in trusted AI would promote the further spread of AI applications by allowing users to feel comfortable with AIs that affect their daily lives.
This synthesis paper covers my exploration of counter-AI, a subfield of trusted AI. In a world full of artificial intelligence, one of the biggest threats would be the presence of adversaries, or attackers, who can intentionally cause AI systems to misbehave. Thus, we seek the prevention of all possible attacks so that users can always rely on AI systems. The study of counter-AI, also known as adversarial AI, deals with the methodologies used by adversaries to degrade or manipulate AI systems. Given an understanding of different attacks, our main objective is to build an AI model that is unaffected by these attacks. In particular, my study was motivated by the following questions:
- Can AI be subverted/co-opted to perform sub-optimally or change its goal (from the goal it was sup- posed to achieve)?
- How can we defend AI systems against being subverted or co-opted?
In this paper, I cover a detailed explanation of counter-AI to the extent to which I have explored and a discussion about how this study has impacted my perspectives on AI.